
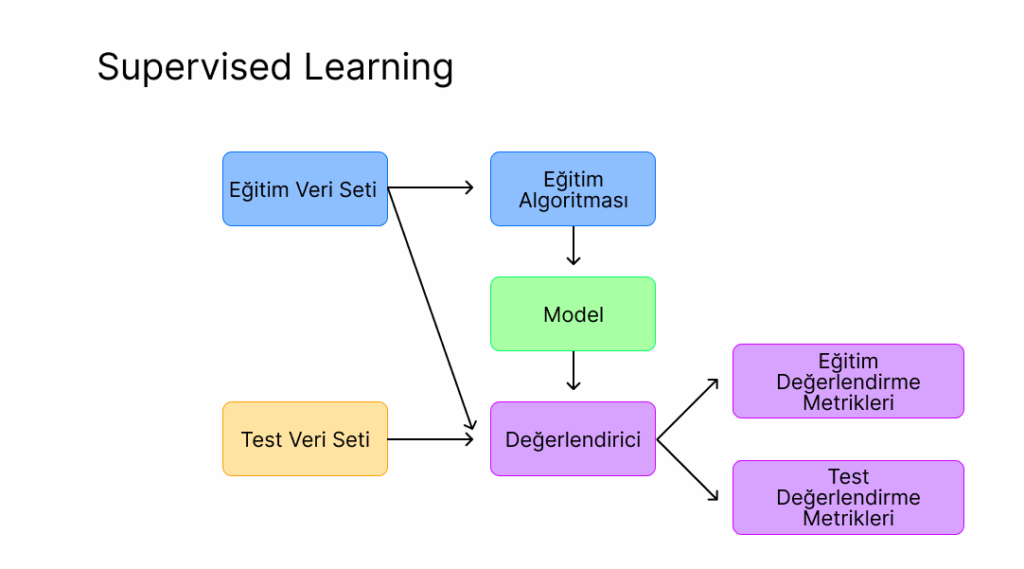
MatriksIQ uygulaması Yapay Zekâ Analizi V2 kapsamında sunulan modül ile sağlanan tüm modellemeler ve öğrenmeler, predictive modeling (tahmine dayalı modelleme) makine öğrenmesi modellemeleri kapsamında supervised learning (denetimli öğrenme) ile gerçekleştirilmektedir.
Makine öğrenmesi gerçekleşmiş olaylar üzerinden öğrenen ya da performans geliştirmeyi hedefleyen sistemleri oluşturmayı hedefleyen bir yapay zekâ alt kümesidir. Makine öğrenmesinde kullanılan algoritmalar supervised learning (denetimli öğrenme) ve unsupervised learning (denetimsiz öğrenme) algoritmalarıdır. Supervised learning sınıflandırma ve regresyon olarak iki ana kategoriye ayrılır.
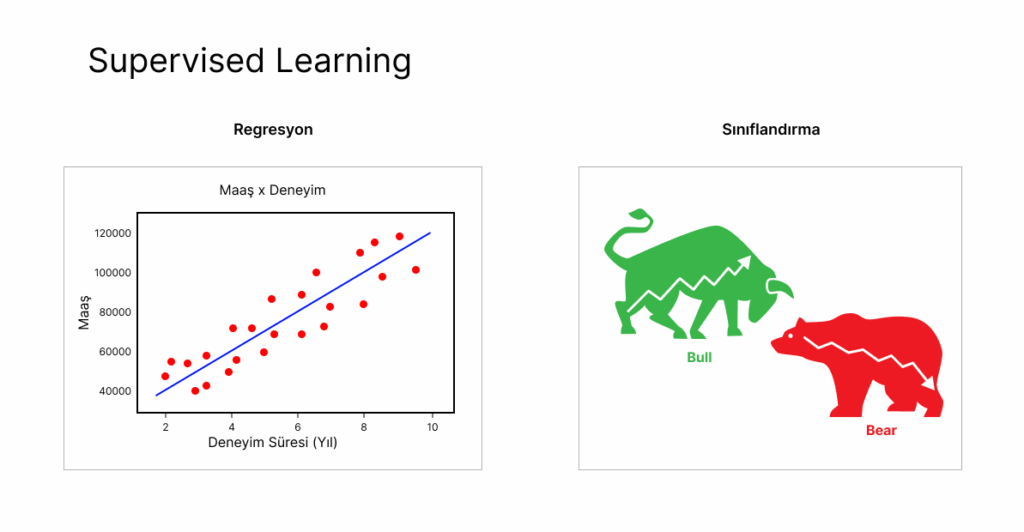
Sınıflandırma: Sınıflandırma problemlerinde, model, girdiyi belirli kategorilere ayırmayı öğrenir. Örneğin, bir e-posta sınıflandırma modelinde, e-postaların spam ya da spam olmadığını belirlemek için sınıflandırma algoritmaları kullanılır.
Resgresyon: Regresyon problemlerinde ise model, girdilerle sürekli bir çıktıyı tahmin etmeyi öğrenir. Örneğin, ev fiyatlarını tahmin etmek için kullanılan bir model, bir dizi girdi (evin büyüklüğü, oda sayısı, konumu vb.) kullanarak evin fiyatını tahmin eder.
Tahmini modelleme, makine öğrenimi (ML) ve istatistiklere dayanan, gelecekteki sonuçları veya eğilimleri tahmin etmek için geçmiş ve güncel verileri kullanan bir tekniktir. Veri kümeleri içindeki kalıpları ve ilişkileri analiz ederek, bilinmeyen gelecekteki olaylar hakkında tahminler üretebilen hesaplamalı modeller oluşturur. Bu yetenek, çok sayıda sektörde bilgili karar alma, stratejik planlama ve süreçleri optimize etmek için hayati önem taşır ve geçmişi basitçe tanımlamanın ötesine geçerek geleceği tahmin eder.
Bu yöntemde daha önceden gerçekleşen örnek olaylar verilerek, eğitim sürecinden geçirilir ve yeni oluşacak olan örnek olay için tahmin edilen sonucun oluşup oluşmayacağı tahmin edilir.
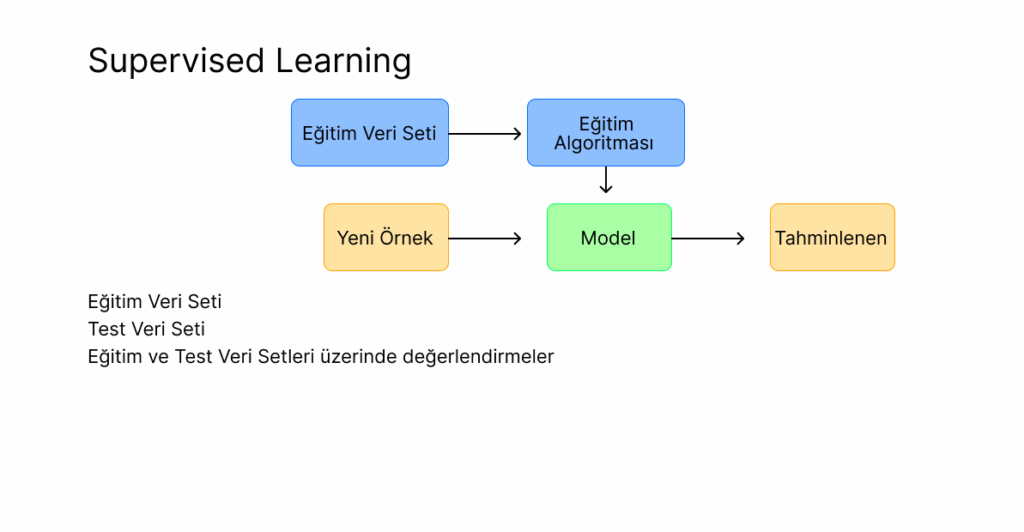
MatriksIQ’da yapay zekâ model oluşturma ekranında model girdilerini seçtiğimiz adımda (sembol, periyot, tarih aralığı) ve hedef kriterleri adımında (win size, look ahead,getiri vb) yaptığımız seçimlerle birlikte Traning Set (Eğitim Seti) oluşturulmuş olur. Eğitim seti oluşturulduktan sonra bir eğitim algoritması seçilir. Bu eğitim algoritmaları bize bir model oluşturur ve yeni gelen örnekler için bir tahmin oluşturmaya başlar.
Buradaki her bir örnek excelin bir satırı şeklinde olur. Olay sonucuna dair hedef yani gerçekleşip gerçekleşmeyeceği bilgisi de her satırın sonuna tanımlanır.

MatriksIQ’da bu hedefin gerçekleşip gerçekleşmeyeceği Look Ahead olarak tanımlanan ileriye dönük olarak istenen hedefin aranacağı bar sayısı içerisinde hedefe bakılarak belirlenir. Örneğin alttaki seçimler ile ilerlendiğinde Günlük periyot seçimiyle, önümüzdeki 10 gün içinde %3 oranında yükseliş hedefine ulaşılıp ulaşılmayacağı aranır.
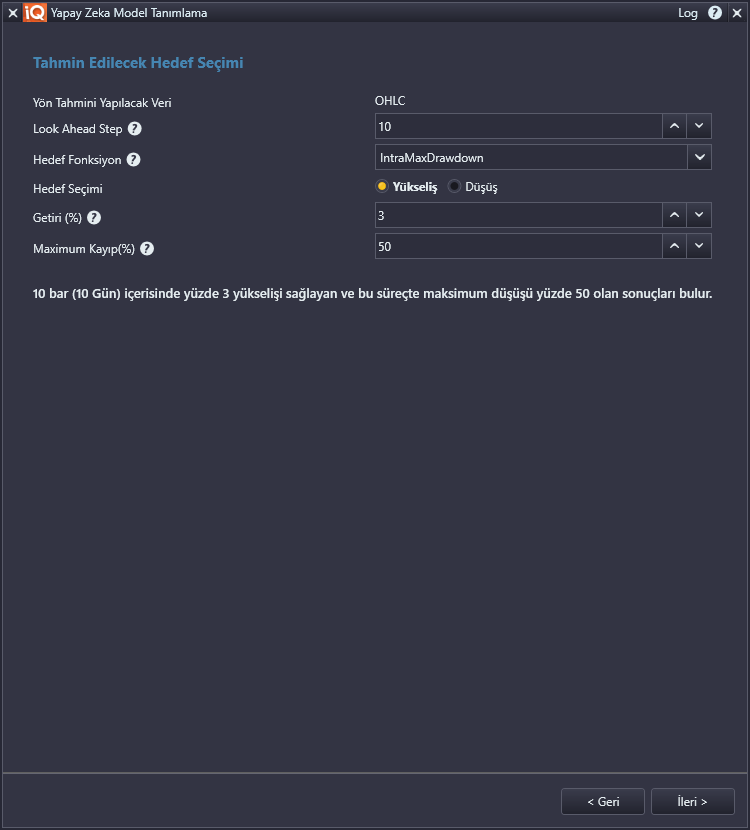
Not: Ters yönlü fiyat hareketlerinin (düşüş yönlü) işlemler üzerinde oluşturacağı Maksimum kayıp etkisini dikkate almadan ilerlemek üzere Maksimum Kayıp değeri yüksek tutulmuştur.
Böyle bir hedef için exceldeki her kolona her bir tahmin edilecek bar için bir satır eklendiğini ve bununla modelin öğrenmesinin sağlanacağını düşünebiliriz.
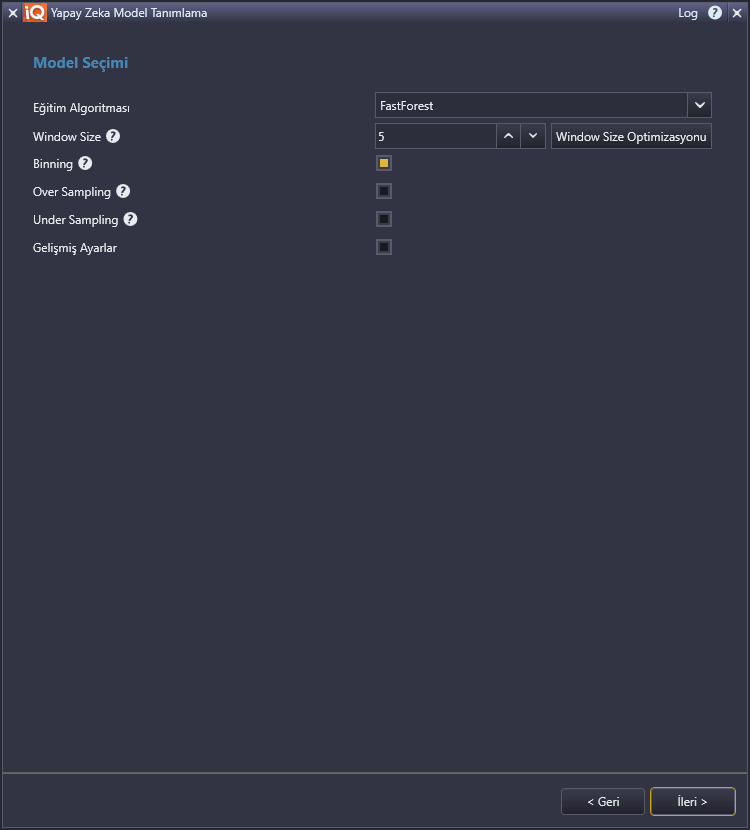
Burada ayrıca Window Size kavramından bahsetmemiz gerekir. Geçmişte bakılacak bar sayısı Window Size değerine karşılık gelir. Örneğin Window Size değeri 5 ise, IQ örneğimizde geçmişteki 5 bara bakarak, ilerideki 10 bar içinde istenen yükselişin yakalanıp yakalanmayacağı tahmin edilir.
Model oluşturma sırasında sembol seçimi ile ilgili esnek bir yapı sunulur. En üst bölümde yer alan tek ya da çoklu sembol seçim alanı dışında Farklı Sembol Ekle seçeneği sunulmaktadır.
Sadece üst bölümdeki sembol seçimi ile ilerlendiğinde her bir sembolün her bir bar datası için bir satır oluşturulur. Window Size kadar (kaydırılmış bir window gibi) kolon açılış, kapanış, yüksek, düşük gibi değerler için ayrı ayrı eklenir. Tek bir sembol seçildiğinde satır sayısı seçilen bar sayısına eşit durumdadır. Eğer birden fazla sembol seçilirse alta satır olarak diğer sembollerin verileri de eklenir. Dolayısıyla modele girdi olan örnek sayısı arttırılmış olur.
İndikatör eklendiğinde OHLC (Açılış-Kapanış-Yüksek-Düşük) verilerinin yanına bir kolon daha eklenmiş olur.
Farklı sembol ekle seçimi ile yapılan sembol eklemesinde ise yine indikatör gibi kolon olarak dahil etme şeklinde ilerlenir. Örneğin ilk 4 kolon üstteki sembol seçimi alanında seçilen sembolün OHLC kolonu iken, sonraki 4 kolon bir sonraki sembolün OHLC değerleri olur. Bu durumda örnek sayısı artmazken, daha fazla veri ile örnek oluşturulmuş olur.
Bu farklılığın tahmin sonuçlarına etkisi hala deneme aşamasındadır. Hem MatriksIQ için hem de farklı derin öğrenme metotlarında satır ya da kolon verisinin fazla olmasının farkları araştırılmaktadır.
Model oluşturma için veri seti girdilerine ait seçimler ve eğitim algoritması seçimi sonrasında eğitim adımına gelinir. Oluşturulan veri setinin %80’lik kısmı eğitim verisi için kullanılmak üzere ayrılır. Kalan %20’lik kısmı ise test verisi olarak ayrılır. Model eldeki verinin %80’i ile eğitildikten sonra, kalan veri ile -ki bu veri modelin hiç görmediği bir veri setidir- test edilir.
Model Değerlendirme #
Model evaluation yani model değerlendirmesi, makine öğrenimi modellerinde farklı değerlendirme metriklerini kullanarak modelin performansı hakkında bilgi edinmemizi sağlayan bir süreçtir.
Model değerlendirmesi, şu sorulara cevap arar:
- Model ne kadar doğru tahminler yapıyor?
- Hangi durumlarda hata yapabilir?
- Veri setinin hangi bölgeleri model için zorluk oluşturuyor?
Bir modelin ne kadar iyi çalıştığını anlamak, modelin gerçek dünya verileri üzerinde ne kadar güvenilir olabileceğini gösterir. Bu, modelin günlük kullanımda veya gerçek uygulamalarda ne kadar etkili olabileceğini anlamak için önemlidir.
Model değerlendirmede kullanılan metrikler ile anlamlandırılır;
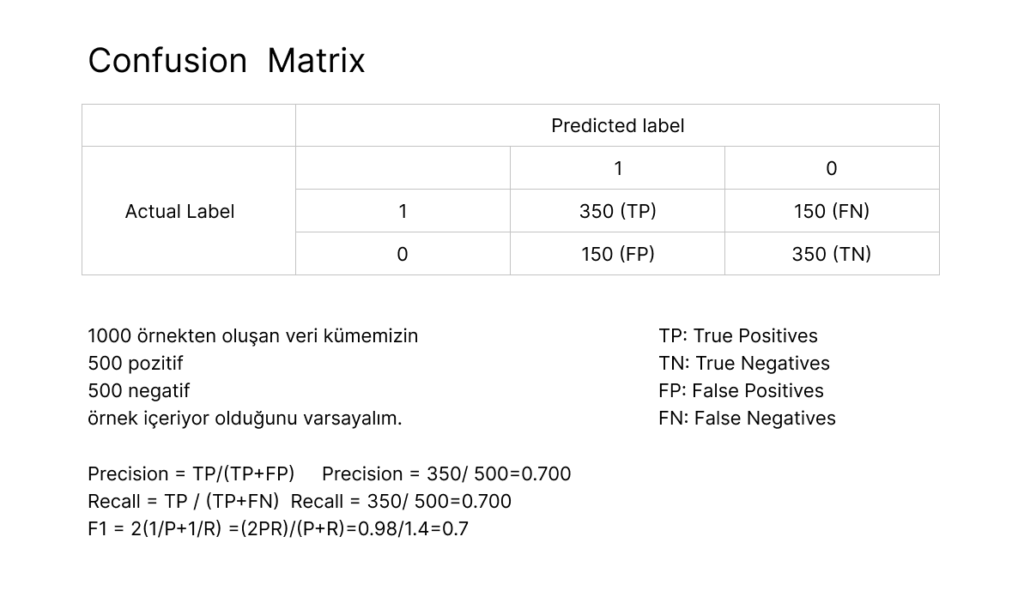
Accuracy Score #
Genel doğruluk oranını gösterir. Doğru tahmin edilen toplam örnek sayısının tüm örnek sayısına oranıdır.
Precision Score #
İlgilenilen sınıfın doğru olarak tahmin edilme oranını gösterir.
Recall Score #
Gerçekten pozitif olan durumların ne kadarının doğru bir şekilde tahmin edildiğini ölçer
F1 Score #
Precision ve recall’un harmonik ortalamasını alarak dengelenmiş bir metrik sağlar. Yüksek bir f1 skoru, hem precision hem de recall’ un yüksek olduğunu gösterir.
Hesaplamalar #
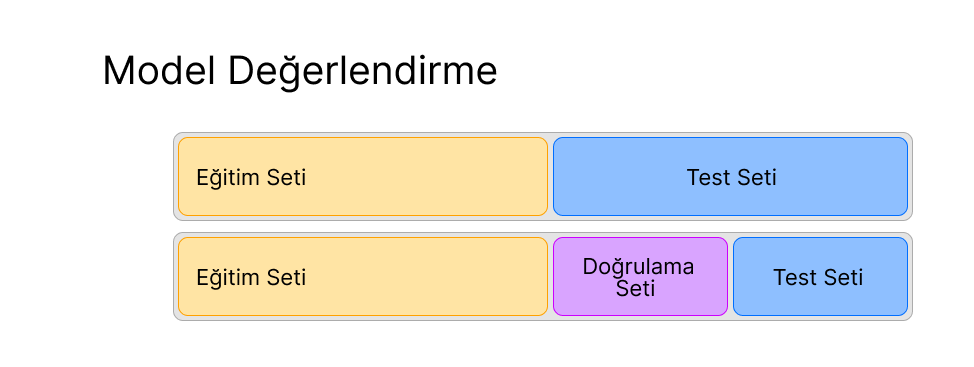
Eğitim/Test Bölümleme Tekniği #
Veri setini eğitim ve test olarak ayırmamıza yardımcı olur. Eğitim verisiyle eğitip test verisiyle modelimizin ne kadar öğrendiğini ölçmemizi yani modeli değerlendirmemizi sağlar.
Modelin performansı eğitim seti üzerinden bakıldığında yüksek çıkabilir. Burada ayrıca modeli hiç görmediği bir veri ile denemek için modele giren veri bölünür. %80-%20 olarak verilen eğitim/test bölümlemesi buna aittir ve ekranda değiştirilebilir durumdadır. Test kısmındaki getiri modelin nasıl çalıştığının en büyük kanıtıdır. Tabi eğer eğitim verisi oranları zaten düşük ise test verilerinin başarılı olması da beklenemez.
Örnek Üzerinden Anlatım #
Yukarıdaki örnekte;
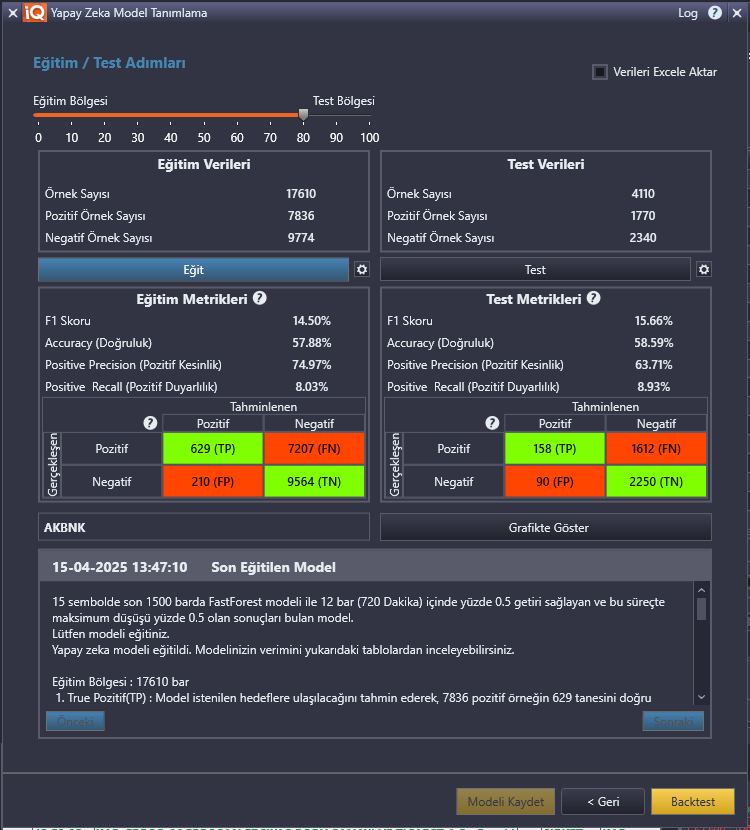
Veri kümesinin eğitim için ayrılan %80’lik kısmında toplam 17610 örnek bulunmaktadır.
Bu örneklerden 7836 tanesi tahmin için seçtiğimiz kriterlere uygun bulunmuş ve pozitif olarak işaretlenmiştir.
9774 örneğin ise seçtiğimiz kriterlere uygun olmadığını ve negatif olarak işaretlendiğini görmekteyiz.
Modelimizi değerlendirirken öncelikle eğitim metriklerini kontrol edebiliriz. Model eğitime ayrılan veri setinde 7836 pozitif örnekten 629 tanesini doğru olarak işaretlemiş. Yeşil-kırmızı renklendirilen tabloda TP (true positive) olarak gösterilmekte. Toplam pozitif örneklerin %8.03’üne denk gelen bu oran Positive Recall alanında verilmekte. Kalan 7207 pozitif örnek ise model eğitiminde negatif olarak yani başarısız şekilde işaretlenmiş. Kırmızı ile renklendirilen kutucuklar False yani hatalı işaretlenmiş sonuçları içerir. 7207 örnek hatalı şekilde pozitif olması gerekirken negatif olarak işaretlenmiş. 210 örnek ise pozitif değilken pozitif olarak işaretlenmiş. Tabloda FP (false positive) olarak kırmızı zeminle gösterilmektedir. Veri kümesinin toplam eğitim örnek sayıları ile eğitim metriklerini kıyaslayarak modelimizin ne kadar iyi eğitildiğini görebiliriz. Bu model için başarılı olarak düşünebileceğimiz değer, tahmin sonuçlarına göre seçtiğimiz kriterlere uygun yani pozitif olarak belirlediği barların (TP+FP) %74.97 oranında doğru olmasıdır. Bu değer Positive Precision alanında verilir ve önemli bir değerlendirme kriteridir. Modelimiz az tahmin yapsa da (Positive Recall %8.03) yaptığı tahminlerin başarı oranı yüksektir.
Model değerlendirmede esas aldığımız test veri kümesindeki metriklerimiz olacaktır. Ancak eğer eğitim metrikleri başarılı değilse test metriklerine geçmek çok da anlamlı değildir. Bunun yerine model girdilerini düzenleyerek daha iyi sonuçlara ulaşılması daha verimli olacaktır.
Bu model test metriklerinde pozitif olarak belirlediği sonuçların %63.71’ini doğru olarak tahmin etmiştir. Toplam pozitiflerin ise %8.93’ünü bulabilmiştir.
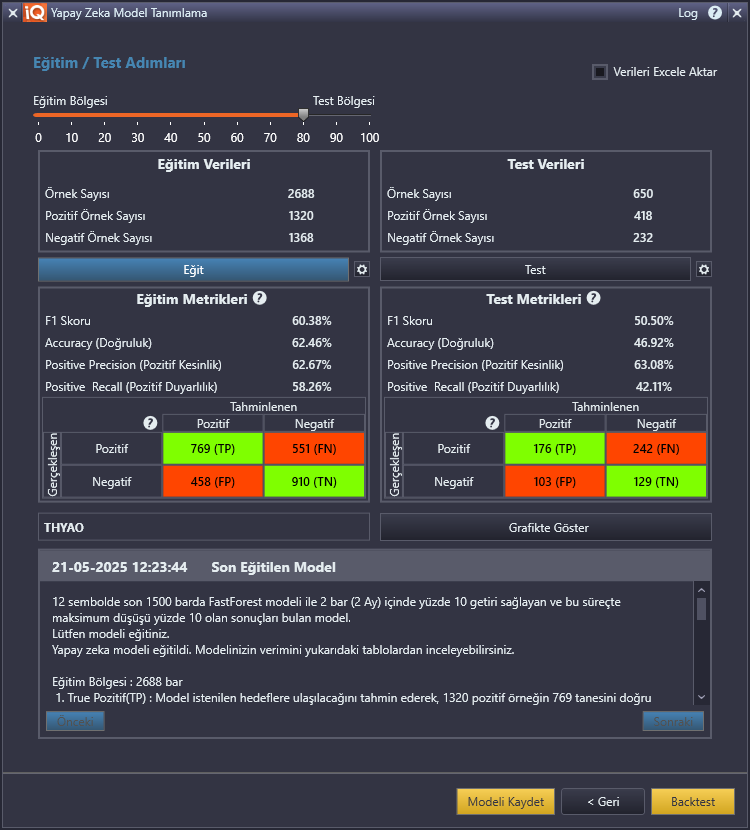
Yukarıdaki bir diğer örnekte modelin eğitim veri kümesindeki pozitif örneklerin %58.26’sını bulabildiğini, pozitif işaretlediği örneklerin %62.67’sinin doğru işaretlendiğini görüyoruz. Tercihimiz eğitim veri setinde çok daha iyi sonuçlar elde etmek olmalıdır. Seçtiğimiz kriterler, zaman aralıkları, eğitim algoritması sonuçlarımızda belirleyici önemli faktörlerdir. Eğitim metrikleri çok yüksek değerlere ulaşmasa da test metrikleri (modelin hiç görmediği bir veri seti ile tahmin yapıyor olmasına rağmen) bu model için daha başarılı değerlendirilebilir. Test veri kümesindeki pozitif örneklerin %42.11’ini bulabildiğini, pozitif işaretlediği örneklerin %63.08’inin doğru işaretlendiğini görüyoruz. Test metrikleri bizim için model ile çalışmaya başladığımızda alacağımız sonuçlar için en yakın gösterge olacaktır.
Test metriklerinin bir adım ötesinde de yapay zekâ tahmin sonuçlarına dayalı bir strateji ile işlem yaptığımızı ve elde edeceğimiz getiriyi gösteren backtest önemli bir değerlendirme kriteri olarak MatriksIQ ile sunulmaktadır.
Test metrikleri ile backtest arasındaki en temel fark, backtest hesaplamalarında, tahminin üretildiği bar ile pozisyon açıldıktan sonra gelen ara pozitif tahmin sonuçlarının işleme dahil edilmemesidir. Pozisyon model oluşturulurken girilen getiri seviyesine ya da maksimum kayıp değerine ulaşana kadar yeni pozisyon açılmaz. Bu seviyelere ulaşıldığında pozisyon kar ya da zarar ile kapatılır. Sonrasında ilk gelen pozitif tahmin sinyali ile yeniden pozisyon açılır.
Yukarıda test metriklerini yorumladığımız modelin backtest sonuçlarına bakarak kıyaslama yapalım.
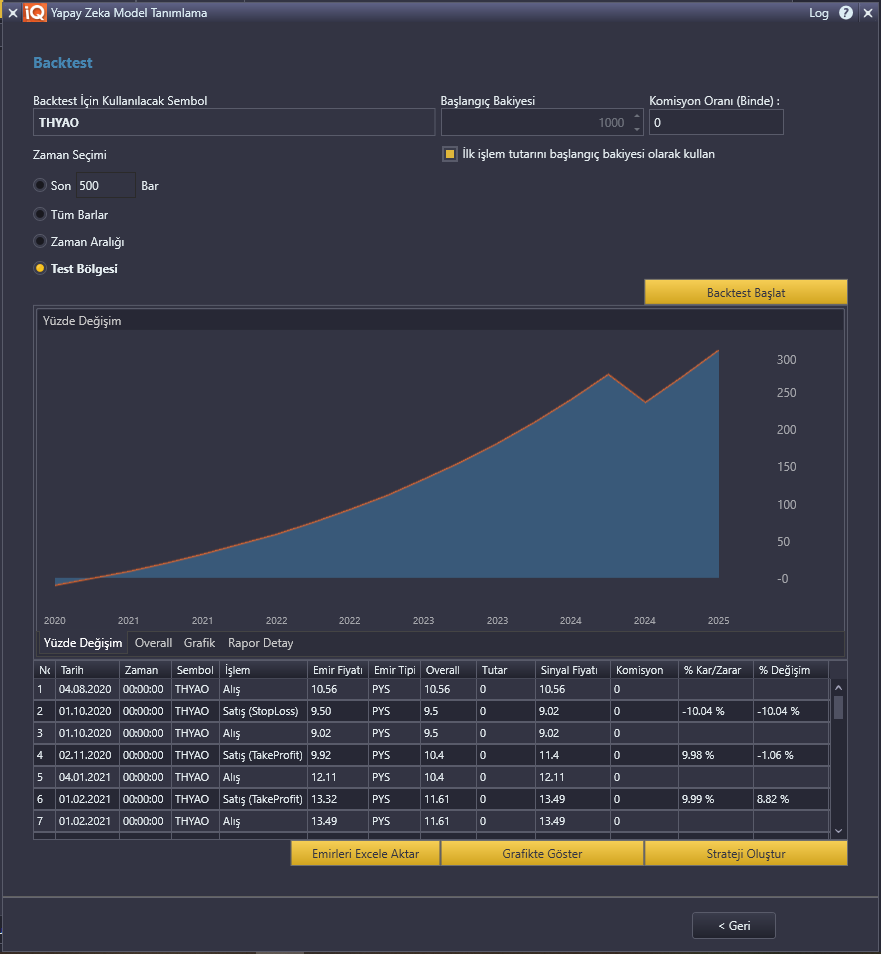
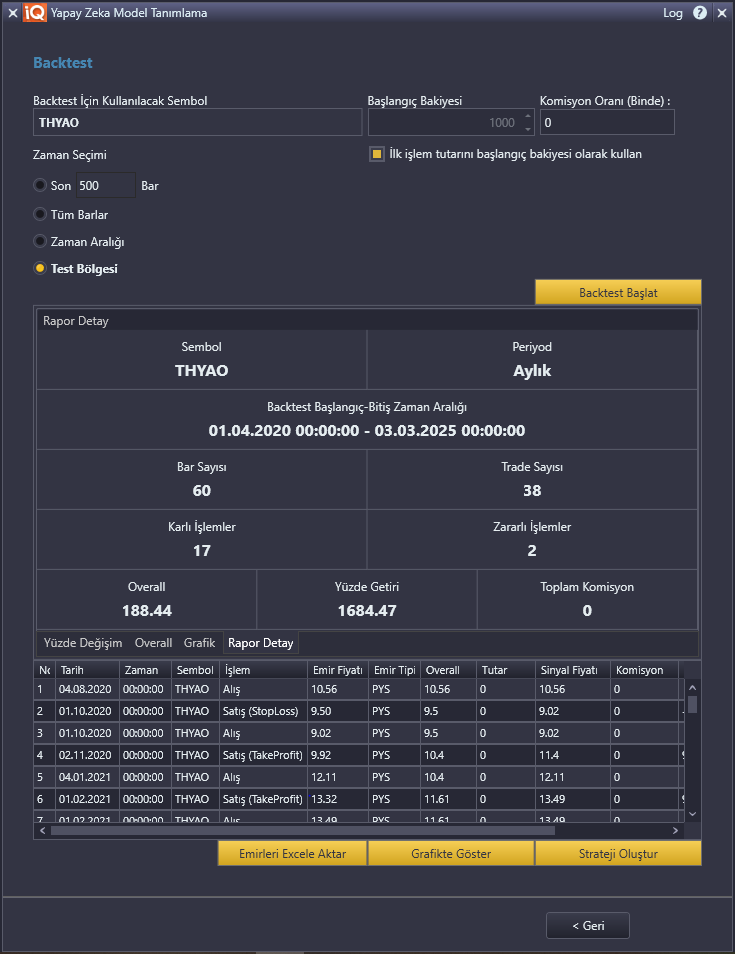
Tahmin sonuçlarına göre çalışan stratejimiz toplamda 38 kez işlem yapmıştır. 19 tane pozisyon açma ve 19 tane pozisyon kapama işlemi yapılmıştır. Backtest’imizin çalışacağı zaman aralığını test metriklerinin olduğu zamanla aynı hale getirmek üzere Zaman Seçimi seneklerinden Test Bölgesi seçeneğini işaretleyerek backtest’imizi başlatabiliriz. Aynı zaman aralığında test metriklerinde çok sayıda tahmin yapıldığını görebiliriz. Ancak backtest işlemlerinde zaten pozisyondaysak yeni tahmin sonucu dikkate alınmadığı için işlem sayısı oldukça düşmektedir. Bu da getiriyi önemli ölçüde değiştiren bir faktördür. Bu nedenle oluşturmuş olduğunuz modeli değerlerken öncelikle eğitim metriklerinin değerlendirilmesi, sonrasında test metriklerinin değerlendirilmesi ve ayrıca backtest ile işlemlerin değerlendirilmesi en doğru ve gerçek hayat deneyimine yakın sonuçlara ulaşmanızı sağlayacaktır. Model üzerinden strateji oluşturarak gerçek zamanlı olarak işlemlere başladığınızda elde edeceğiniz getiriye en yakın sonuçları bu şekilde ölçebilir ve modelinizi doğru değerlendirebilirsiniz.



